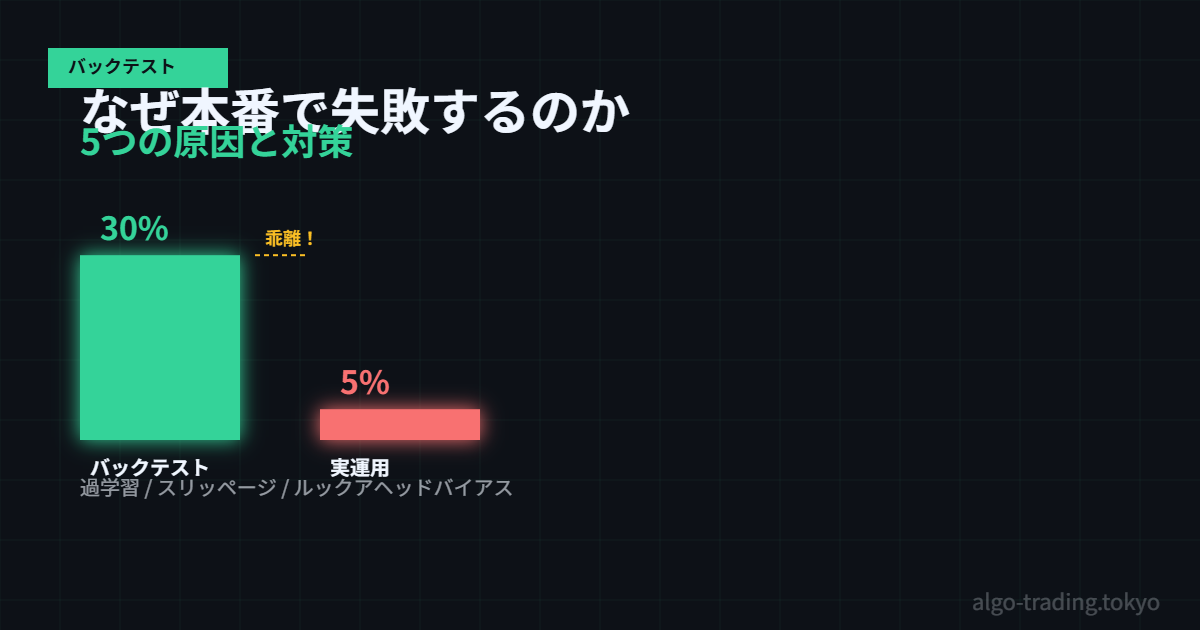
先日、3ヶ月かけて作ったBOTを本番稼働させたんですが。。。バックテストでは年利30%超えだったのに、最初の1ヶ月でマイナス5%になってちょっと焦りました。「あれ、コードにバグがあるのかな」と思ってデバッグしていたら、バグではなくて「バックテストの罠」にはまっていたことがわかりました。同じ経験をしている方、きっと多いと思うので記事にします。
バックテストと実運用が乖離する主な原因
結論から言うと、原因は1つではありません。複数の要因が重なって「バックテストではよくても本番では駄目」という状況を生み出します。以下で一つひとつ解説します。
原因1:スリッページと手数料を無視している
バックテストで最もよくある見落としがこれです。終値で売買できると仮定したシミュレーションは、実際には成立しません。特に流動性の低い銘柄では、指値が通らずに想定外の価格で約定することが多いです。
import backtrader as bt
class MyStrategy(bt.Strategy):
def __init__(self):
self.sma5 = bt.indicators.SMA(self.data.close, period=5)
self.sma25 = bt.indicators.SMA(self.data.close, period=25)
def next(self):
if self.sma5[0] > self.sma25[0] and not self.position:
self.buy()
elif self.sma5[0] < self.sma25[0] and self.position:
self.sell()
# ★スリッページと手数料を必ず設定する
cerebro = bt.Cerebro()
cerebro.broker.setcommission(commission=0.001) # 0.1%の手数料
cerebro.broker.set_slippage_perc(0.0005) # 0.05%のスリッページ
手数料とスリッページを入れるだけで、バックテストの成績が大きく変わることがあります。僕の場合、これを入れたら年利30%が18%まで落ちました(笑)。
原因2:過学習(カーブフィッティング)
パラメータを「過去データに最適化」しすぎると、未来のデータには全く通用しなくなります。「SMAの期間を3から100まで全部試して一番良かった値を使う」というのが典型的な過学習です。
import numpy as np
def walk_forward_test(df, train_ratio=0.7):
n = len(df)
train_size = int(n * train_ratio)
train_data = df.iloc[:train_size]
test_data = df.iloc[train_size:]
best_period = None
best_return = -np.inf
for period in range(5, 50):
sma = train_data['Close'].rolling(period).mean()
signal = (train_data['Close'] > sma).astype(int).shift(1)
ret = (train_data['Close'].pct_change() * signal).sum()
if ret > best_return:
best_return = ret
best_period = period
sma_test = test_data['Close'].rolling(best_period).mean()
signal_test = (test_data['Close'] > sma_test).astype(int).shift(1)
test_return = (test_data['Close'].pct_change() * signal_test).sum()
print(f"最適期間(訓練): {best_period}")
print(f"訓練データリターン: {best_return:.4f}")
print(f"テストデータリターン: {test_return:.4f}")
return best_period, test_return
原因3:サバイバーシップバイアス
「現在上場している銘柄のみ」でバックテストをすると、過去に上場廃止になった銘柄が除外されます。これにより成績が過大評価される現象です。製造メーカー株でテストするときは特に注意です。
原因4:ルックアヘッドバイアス(未来参照)
「今日の終値で判断して、今日中に売買する」というロジックは実際には不可能です。終値が確定するのは引け後なので、翌日の始値でしか対応できません。
import pandas as pd
# ❌ 悪い例:当日終値でシグナルを出して当日約定
df['signal'] = (df['Close'] > df['SMA25']).astype(int)
df['return'] = df['Close'].pct_change() * df['signal']
# ✅ 良い例:シグナルを1日ずらして翌日始値で約定
df['signal'] = (df['Close'] > df['SMA25']).astype(int).shift(1)
df['return'] = df['Open'].pct_change() * df['signal']
たった1行の .shift(1) の有無で結果が大きく変わります。僕はこれを知らずに半年間バックテストしてました(苦笑)。
原因5:相場環境の変化(レジームチェンジ)
2020〜2021年のコロナ相場と2024〜2025年の相場では、全然性質が違います。ある期間で最適化したパラメータが、相場環境が変わったあとでは全く効かなくなることがあります。定期的にパラメータを再最適化するか、相場環境を判定するロジックを入れることが対策です。
まとめ
バックテストと実運用が乖離する主な原因として、①手数料・スリッページの未考慮、②過学習、③サバイバーシップバイアス、④ルックアヘッドバイアス、⑤相場環境の変化の5つを紹介しました。全部いっぺんに解決しようとすると大変なので、まず「.shift(1)の確認」と「手数料の設定」から始めるのがおすすめです。僕も今リファクタリング中で、次回はウォークフォワードテストの実装例をもう少し詳しく書こうと思います。同じ失敗をした方はコメントで教えてください!
関連サービス
【FANTAS study】 — 税金・資産運用を体系的に学べるオンラインスクール。投資初心者から実践派まで対応。
【マネカツ】 — 資産運用・株式投資を学ぶオンラインセミナー。正しい知識でバックテストを活かした運用を。
Buyboost(バイブースト) — 株式・投資情報を効率的に活用するためのサービス。