なぜ2026年に機械学習×株価予測が注目されるのか
「AIが株を予測する時代」——これはもはやSFの話ではありません。2026年現在、機械学習を使った株価予測・アルゴリズムトレードは個人投資家にも手の届く技術になっています。Pythonとscikit-learnがあれば、プログラミングの基礎知識さえあれば誰でも株価予測モデルを作り始めることができます。
本記事では、scikit-learnのランダムフォレストを使って「翌日の株価が上がるか下がるか」を予測する分類モデルを、ゼロから実装する方法を解説します。
機械学習で株価予測をする際の基本的な考え方
株価予測に機械学習を使う場合、「明日の株価が上がるか下がるか」という分類問題として定式化するのが一般的です。テクニカル指標(移動平均、RSI、MACDなど)を特徴量(Features)として使い、「翌日終値が前日より高いか低いか」をラベル(Label)として設定します。
必要なライブラリのインストール
pip install yfinance pandas numpy scikit-learn matplotlib ta特徴量エンジニアリング
import yfinance as yf
import pandas as pd
import numpy as np
import ta
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
import warnings
warnings.filterwarnings('ignore')
# ソフトバンクグループの株価データを取得
ticker = '9984.T'
df = yf.download(ticker, start='2022-01-01', end='2026-05-01', auto_adjust=True)
df = df[['Open', 'High', 'Low', 'Close', 'Volume']].copy()
# 移動平均との乖離率
df['SMA5_ratio'] = df['Close'] / df['Close'].rolling(5).mean() - 1
df['SMA20_ratio'] = df['Close'] / df['Close'].rolling(20).mean() - 1
# RSI(14日)
df['RSI_14'] = ta.momentum.RSIIndicator(close=df['Close'], window=14).rsi()
# MACD
macd_ind = ta.trend.MACD(close=df['Close'])
df['MACD'] = macd_ind.macd()
df['MACD_Signal'] = macd_ind.macd_signal()
df['MACD_Hist'] = macd_ind.macd_diff()
# ボリンジャーバンドの位置
bb = ta.volatility.BollingerBands(close=df['Close'])
df['BB_pband'] = bb.bollinger_pband()
# ボラティリティと出来高比率
df['Volatility'] = df['Close'].pct_change().rolling(20).std()
df['Volume_ratio'] = df['Volume'] / df['Volume'].rolling(20).mean()
# 前日比リターン
df['Return_1d'] = df['Close'].pct_change(1)
df['Return_5d'] = df['Close'].pct_change(5)
# ターゲット: 翌日終値が上がれば1
df['Target'] = (df['Close'].shift(-1) > df['Close']).astype(int)モデルの学習と評価
feature_cols = [
'SMA5_ratio', 'SMA20_ratio', 'RSI_14',
'MACD', 'MACD_Signal', 'MACD_Hist',
'BB_pband', 'Volatility', 'Volume_ratio',
'Return_1d', 'Return_5d'
]
df_clean = df[feature_cols + ['Target']].dropna()
X = df_clean[feature_cols]
y = df_clean['Target']
# 時系列データは時間順に分割(ランダム分割はNG!)
train_size = int(len(X) * 0.8)
X_train, X_test = X.iloc[:train_size], X.iloc[train_size:]
y_train, y_test = y.iloc[:train_size], y.iloc[train_size:]
# ランダムフォレストモデルの学習
model = RandomForestClassifier(
n_estimators=200,
max_depth=6,
min_samples_split=20,
random_state=42,
n_jobs=-1
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
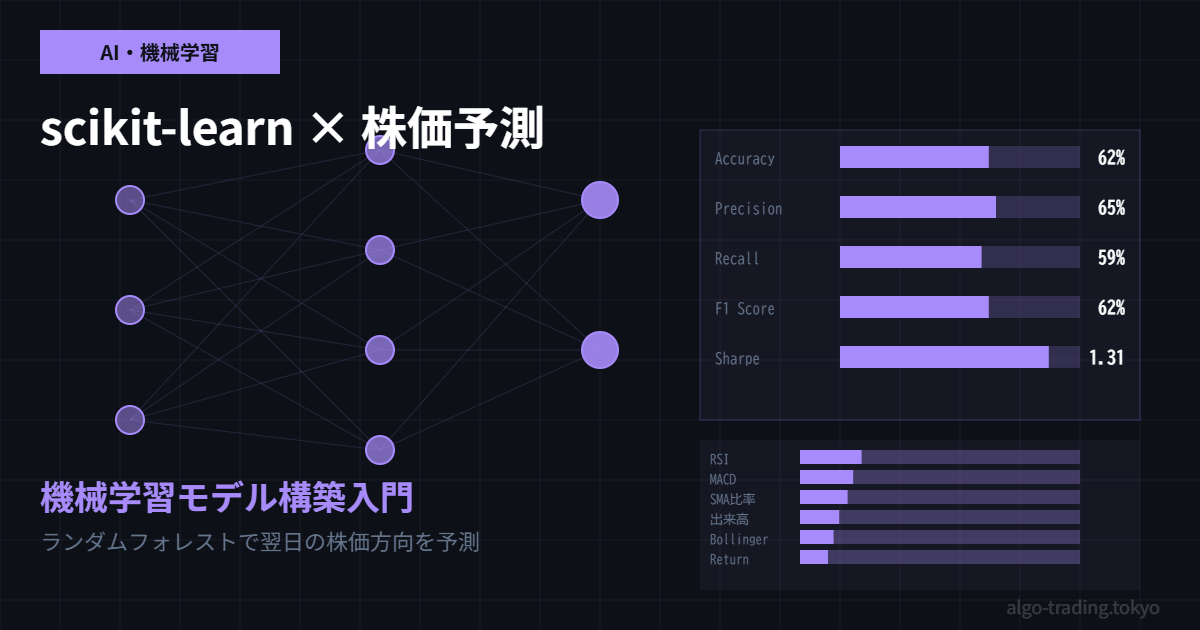
print(f"テスト精度: {accuracy_score(y_test, y_pred):.2%}")
print(classification_report(y_test, y_pred, target_names=['下落', '上昇']))特徴量の重要度を確認する
import matplotlib.pyplot as plt
importance_df = pd.DataFrame({
'feature': feature_cols,
'importance': model.feature_importances_
}).sort_values('importance', ascending=True)
fig, ax = plt.subplots(figsize=(10, 6))
ax.barh(importance_df['feature'], importance_df['importance'], color='#7c3aed', alpha=0.8)
ax.set_xlabel('重要度スコア')
ax.set_title('特徴量の重要度(ランダムフォレスト)')
plt.tight_layout()
plt.show()予測確率を使ったフィルタリング
# 確率が高いシグナルだけ使う
y_prob = model.predict_proba(X_test)[:, 1]
high_conf_buy = (y_prob >= 0.60)
print(f"高確信度の買いシグナル: {high_conf_buy.sum()}件")
print(f"高確信度の勝率: {y_test[high_conf_buy].mean():.2%}")重要な注意点:機械学習の落とし穴
① ルックアヘッドバイアスに注意:将来のデータが特徴量に漏れ込むと、実際には使えない高精度モデルができてしまいます。特徴量には必ず「その日の終値確定後に計算できる値」のみ使いましょう。
② 過学習(オーバーフィット)の罠:学習データで99%の精度が出ても、テストデータで55%しか出ないことは珍しくありません。常に未知データでの精度を重視してください。
③ 精度55〜60%でも実用になりえる:勝率55%でも適切な資金管理と組み合わせれば、長期的に収益を上げることができます。
まとめ
scikit-learnのランダムフォレストを使えば、Pythonの基礎知識があれば誰でも株価予測モデルを作ることができます。次のステップとして、LightGBMやXGBoostなどの勾配ブースティング系モデル、あるいはLSTMなどの時系列ニューラルネットワークへの発展も視野に入れてみてください。機械学習×アルゴトレードの世界は、2026年においても進化を続けています。