バックテスト年利25%→実運用で即損失。。。「過学習」の罠とその対策をPythonで解説
先日、やっとの思いで組んだ自動売買BOTを動かしてみたんですが、バックテストでは年利25%だったのに、最初の2週間でしっかり損失が出ました笑。子供が寝た深夜にPCを開いてその数字を見たときの絶望感、伝わりますかね。。。なぜこんなことが起きるのか調べていくうちに「過学習(オーバーフィッティング)」という概念に行き着いたので、今日はその話をします。
なぜ僕がバックテストの過学習を調べたか
そもそも、バックテストって「過去データで戦略を試す」ことですよね。で、パラメーターをいじりながら「あ、この移動平均の組み合わせだと年利30%になる!」とか「ここでRSI=70を使ったほうがいい!」とかを繰り返していくと、なんかすごいパフォーマンスの戦略ができあがるんです。
でも実際に動かすと全然ダメ。これ、過去データにあまりにも「最適化」されすぎてしまって、未来の新しいデータには全然通用しない状態になっているんです。機械学習でよく言われる過学習と全く同じ概念で、僕みたいな初心者がすごく陥りやすいトラップです。
過学習が起きる主な原因
原因は大きく3つあります。
① パラメーターをいじりすぎ
移動平均の期間とか、RSIの閾値とか、ひたすら最適値を探す「カーブフィッティング」をやりすぎると、その過去データ専用の戦略になってしまいます。
② サンプルが少ない
日本株の場合、年間の取引日数は約240日。短期間のデータだけでテストすると、たまたまその期間に有効だったパターンを拾ってしまいます。
③ インサンプル・アウトオブサンプルの区別がない
最適化に使ったデータと検証に使うデータが同じだと、当然よい結果が出やすくなります。でも実運用はその外側のデータで行われます。
原因④:ルックアヘッドバイアス(未来参照)
「今日の終値で判断して今日中に売買する」というロジックは実際には不可能です。終値が確定するのは引け後なので、翌日の始値でしか対応できません。たった1行の .shift(1) の有無で結果が大きく変わります。僕はこれを知らずに半年間バックテストしてました(苦笑)。
原因⑤:相場環境の変化(レジームチェンジ)
2020〜2021年のコロナ相場と2024〜2025年の相場では、全然性質が違います。ある期間で最適化したパラメータが、相場環境が変わったあとでは全く効かなくなることがあります。定期的にパラメータを再最適化するか、相場環境を判定するロジックを入れることが対策です。
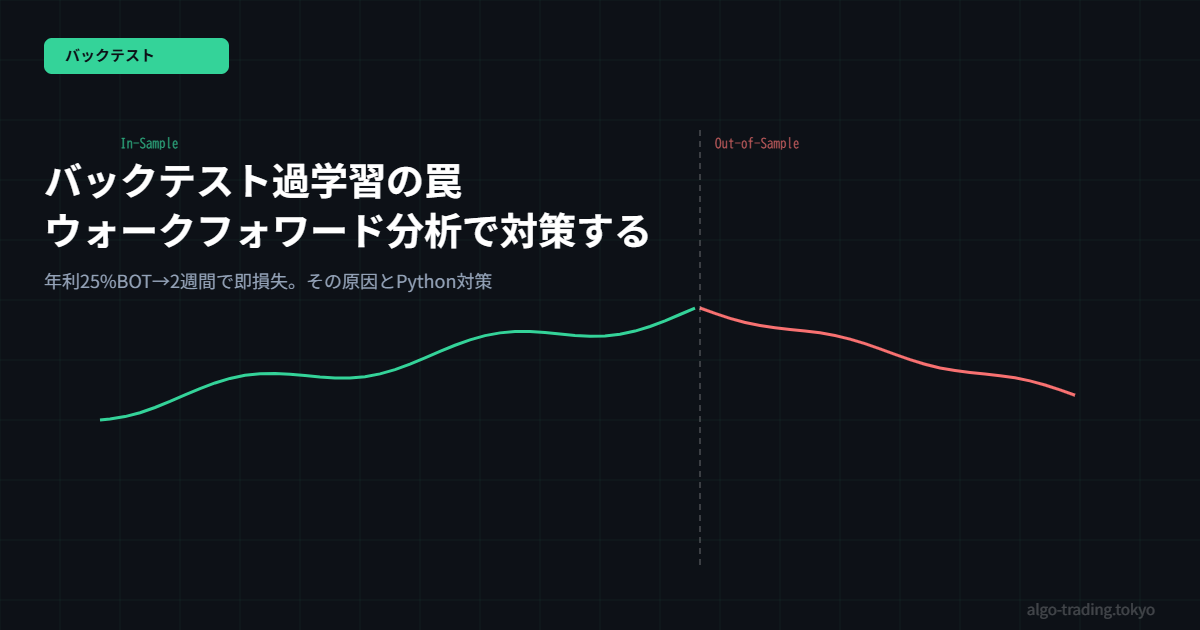
対策① ウォークフォワード分析でPythonを使って検証する
一番効果的な対策が「ウォークフォワード分析」です。データを時系列に分割して、最適化期間(インサンプル)→検証期間(アウトオブサンプル)を繰り返す方法です。
実際にPythonで組んでみたコードを見てみましょう。シンプルな移動平均クロス戦略での例です。
import yfinance as yf
import pandas as pd
import numpy as np
# トヨタ自動車(7203)のデータを取得
ticker = "7203.T"
df = yf.download(ticker, start="2020-01-01", end="2025-12-31")
df = df[['Close']].copy()
def sma_cross_returns(data, fast, slow):
data = data.copy()
data['SMA_fast'] = data['Close'].rolling(fast).mean()
data['SMA_slow'] = data['Close'].rolling(slow).mean()
data['signal'] = np.where(data['SMA_fast'] > data['SMA_slow'], 1, -1)
data['returns'] = data['Close'].pct_change()
data['strategy_returns'] = data['signal'].shift(1) * data['returns']
return data['strategy_returns'].sum()
def walk_forward_analysis(data, in_sample_days=252, out_sample_days=63):
results = []
fast_periods = [5, 10, 20, 25]
slow_periods = [25, 50, 75, 100]
start = 0
while start + in_sample_days + out_sample_days <= len(data):
in_sample = data.iloc[start:start + in_sample_days]
out_sample = data.iloc[start + in_sample_days:start + in_sample_days + out_sample_days]
best_return = -np.inf
best_fast, best_slow = 5, 25
for fast in fast_periods:
for slow in slow_periods:
if fast >= slow:
continue
ret = sma_cross_returns(in_sample, fast, slow)
if ret > best_return:
best_return = ret
best_fast, best_slow = fast, slow
oos_return = sma_cross_returns(out_sample, best_fast, best_slow)
results.append({
'period_start': data.index[start + in_sample_days],
'best_fast': best_fast,
'best_slow': best_slow,
'in_sample_return': best_return,
'out_of_sample_return': oos_return
})
start += out_sample_days
return pd.DataFrame(results)
results = walk_forward_analysis(df)
print(results)
print(f"インサンプル平均リターン: {results['in_sample_return'].mean():.4f}")
print(f"アウトオブサンプル平均リターン: {results['out_of_sample_return'].mean():.4f}")
対策② パラメーターを最初から絞る
もう一つの対策は、そもそもパラメーターの探索範囲を広げすぎないこと。「移動平均の期間は市場の構造から考えて20日か50日くらいが理にかなっている」という仮説を先に立てて、その2つだけで試す、みたいな発想です。
僕の場合、製造メーカー株だと月次・四半期サイクルで機関投資家が動くことが多いので、20日(1ヶ月)と60日(1四半期)の組み合わせを使うことが多いです。これは数値で探したんじゃなくて、「そういう市場構造があるから」という理由付けがある。これが重要です。
対策③ シャープレシオで判断、リターンだけ見ない
バックテストの結果を見るとき、リターン(利益率)だけを見てしまいがちですが、リスクに対してどれだけ稼いでいるかを示す「シャープレシオ」も必ず確認するようにしました。
def calculate_sharpe(returns_series, risk_free_rate=0.001):
excess_returns = returns_series - risk_free_rate / 252
sharpe = excess_returns.mean() / excess_returns.std() * np.sqrt(252)
return sharpe
# 目安: 1.0以上で良好、2.0以上で優秀
シャープレシオが1.0以下の戦略は、バックテストでどんなにリターンが高くても実運用には向かないと思っています。
まとめ:バックテストは「証明」じゃなくて「仮説検証」
バックテストで高いリターンが出ても、それは過去に有効だったというだけで、未来が保証されるわけじゃない。これって頭ではわかっているつもりでも、実際に「年利25%」という数字を見てしまうと舞い上がってしまうんですよね笑。
ウォークフォワード分析を取り入れてから、戦略の「本当の実力」が見えるようになった気がします。インサンプルとアウトオブサンプルのリターン差が小さい戦略を選ぶ習慣をつけてから、少しだけ実運用が安定してきました。個人的には次のステップとして、モンテカルロシミュレーションを使ったドローダウン分析も試してみたいと思っています。同じ悩みを持っている方はぜひウォークフォワード分析を試してみてください。
関連サービス
この記事で紹介した手法を実際に試す際におすすめのサービスです。
![]()